sama-v2-sitemap-implementation-plan.md
raw
· source
Building /sitemap.xml under SAMA v2 — a Claude Code /goal walkthrough
This site has 23 blog posts, 4 SAMA discipline pages, a /sama/v2 spec, a verifier, an example library, and a guides section. None of them are listed in a sitemap. Search engines and AI crawlers have to discover everything by random link-walking from the home page — slow, lossy, and especially bad for the long-tail spec pages that few internal links point at.
This post is the implementation plan for /sitemap.xml, written before the code lands. The plan itself uses two artifacts worth pointing at:
- The
/goalslash command in Claude Code. The 38-line spec I'm working from is checked in atgoal.md— that's the exact/goaltext fed to the agent. It declares Done when, Constraints (anti-fudge), and Load-bearing files to read FIRST. The agent has to read those files before writing any code, and it has to satisfy every Done when clause before declaring done. - SAMA v2 itself. The feature has to land conformant —
/sama/v2/verifyreports 7/7 ✓ on the live site, and breaking it on the way in is what the verifier catches. Every architectural decision below traces to a §4 check.
The combination is what this post is really about. The /goal is the what; SAMA v2 is the how; the verifier is the anti-fudge gate. Each constrains the other in a way that turns "add a feature" into a mechanical exercise.
Why a sitemap, and why now
Three concrete signals:
src/a31_blog.tsalready promises it. The top-of-file comment reads: "this file is just the registry that drives/blog,/blog/:slug, and the sitemap." The promise has been there since the registry was written. The sitemap was always meant to exist; it just didn't.- Empirical chain visibility. The cross-repo measurement posts (dive, ripgrep, n=7 baseline) are exactly the kind of long-tail content that needs explicit sitemap entries — they're not in the navigation, they don't get linked from the home page indiscriminately, and they're the load-bearing artifacts for the "is SAMA worth following" argument.
- AI crawlers index sitemaps preferentially. If the empirical chain is the thing I want to be found, the sitemap is the first place to put it.
The decomposition — three files, one per layer
The /goal text fixes the structure before the agent picks up a keyboard. Mapped onto the four canonical layers:
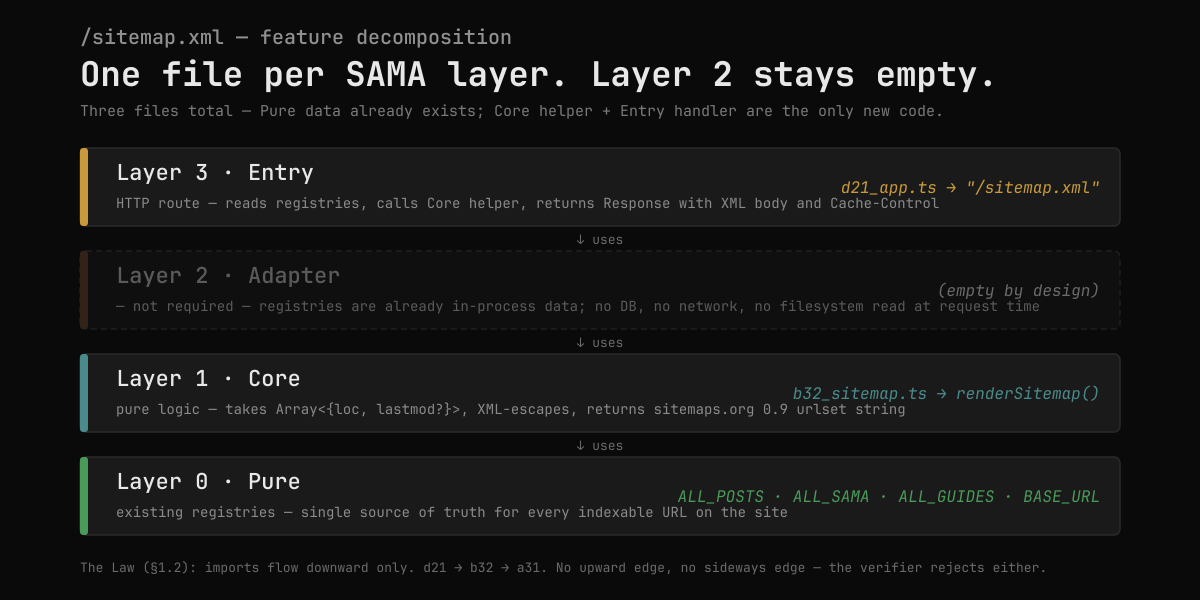
Read top to bottom — imports flow downward, only:
- Layer 3 · Entry —
d21_app.tsgains one route,/sitemap.xml. Its only job: importALL_POSTS+ALL_SAMA+ the static list, call the Core helper, return aResponsewithContent-Type: application/xml; charset=utf-8andCache-Control: public, max-age=3600. No XML construction in the handler — that's the helper's job, and the layer boundary is the reason the helper exists. - Layer 2 · Adapter — empty, by design. This is the structurally interesting part. Sitemaps for most CMSs are an Adapter problem: hit the database, query the post table, emit XML. Here the "database" is already an in-process TypeScript array (
ALL_POSTS). No DB, no network, no filesystem read at request time. So Layer 2 stays empty, and the verifier won't complain because the §4.4 modeled-boundary check only fires when a boundary actually exists. - Layer 1 · Core —
b32_sitemap.ts. Pure logic: takesArray<{ loc: string; lastmod?: string }>, returns the well-formed XML string. No I/O. NoDate.now(). Noprocess.env. Deterministic: the same input array always produces the same output bytes. This is what makes the sibling test cheap to write — six cases, all data-in / string-out. - Layer 0 · Pure — already exists.
ALL_POSTS,ALL_SAMA,ALL_GUIDES, and the canonical base URL froma31_site_config.ts. No new code at this layer; we're consuming what's already there.
The visual property of the diagram — Layer 2 stays empty — is the SAMA-specific reason this feature is so small. In an idiomatic-WordPress shape, a sitemap is a database adapter plus a query plus a renderer plus a cache, four files minimum. In a layer-disciplined shape with the registries already in memory, the adapter dissolves and the feature collapses to one new helper and one new route.
The data flow
Same picture, rotated 90°:
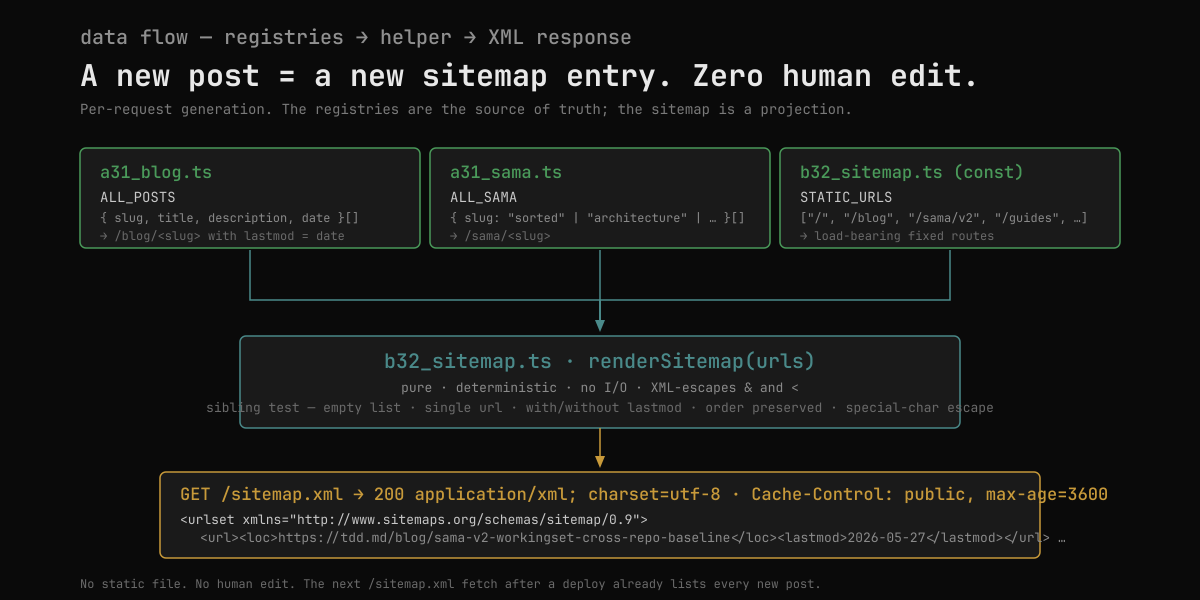
Three registries fan in to one helper; one helper fans out to one response. The shape of that picture is the answer to the question "how does a new blog post get into the sitemap?" — it doesn't get added to anything. It's already in ALL_POSTS (where the new post entry was added when the markdown file was written), so the next /sitemap.xml fetch after the next deploy already lists it. Zero human edit. That's the load-bearing automatic property the /goal calls out:
The sitemap is NOT committed as a static file — it's generated per-request […]. New blog post → next sitemap fetch already includes it without any human edit.
This is also the anti-fudge constraint: if I were to commit a static sitemap.xml, the verifier wouldn't catch it (sitemaps aren't part of the §4 checks), but the property the feature claims would silently rot the first time a post was added without manually editing the file.
What the /goal slash command actually does
For readers unfamiliar with Claude Code's /goal: it's a slash command that takes a structured task description and hands it to the agent with three mandatory sections:
Goal: … ← one-paragraph statement of intent
Done when: … ← bullet list of testable post-conditions
Constraints (anti-fudge): …
Load-bearing files to read FIRST: …
The shape is what makes it useful. Goal is the human-readable intent. Done when is a checklist the agent will be evaluated against — and "all tests pass" is one bullet among many, not the only one. Constraints are the things the agent might be tempted to short-circuit (in this case: "URLs MUST come from existing registries — no second source of truth that can drift"). Load-bearing files to read FIRST prevents the agent from inventing structure that already exists — every existing helper, registry, and pattern is one Read tool call away, but only if the agent is told to look.
The full text of this feature's /goal is in goal.md. Cherry-picking the most load-bearing bullets:
- "URLs are derived from the registries (no hand-maintained slug list)" — fixes the source-of-truth violation that would otherwise emerge over time.
- "Sibling test covers: empty list → valid urlset with no
<url>children; single URL with lastmod; single URL without lastmod; multiple URLs preserve order; XML-escape any&or<in URLs" — fixes the Modeled-tests check (§4.3) before it gets a chance to fail. - "
/sama/v2/verifystill reports 7/7 ✓ (anti-fudge)" — the structural gate. The verifier is the only thing standing between "I shipped a feature" and "I shipped a feature while preserving the property the site is making claims about." - "Site language English-only." — captured from a prior correction, surfaced here so the agent doesn't slip back into Dutch in the response body or error text.
This pattern — /goal as the contract, SAMA v2 as the discipline, verifier as the gate — is the agentic-coding workflow this site is shaped around. The /goal is verbose by design. Verbose-/goal + automatic-/verify is much cheaper than terse-prompt + manual-review.
Mapping the feature onto §4
Each of the seven §4 conformance checks applies. The decomposition above is the answer to each:
| §4 check | How this feature satisfies it |
|---|---|
| §4.1 Sorted | b32_sitemap.ts prefix matches Layer 1, d21_app.ts prefix matches Layer 3. ls src/ reads top-down: a31 (Pure) → b32 (Core) → d21 (Entry). No prefix gap, no out-of-order import. |
| §4.2 Architecture | The number is the layer. Helper at b32 must be pure; handler at d21 may import from anywhere below. The verifier rejects any cross-cluster violation mechanically. |
| §4.3 Modeled-tests | Sibling b32_sitemap.test.ts covers all five Done when test cases. Without the sibling, §4.3 turns red. |
| §4.4 Modeled-boundary | Boundary parsing lives in the registries (already done at module load) and at the helper's input shape (typed Array<{loc, lastmod?}>). The helper doesn't see strings from the wire. |
| §4.5 Atomic | Helper estimated 50–100 LOC; handler closure 15–25 LOC. Both well under the 700-LOC cap. |
| §4.6 The Law (§1.2) | d21 → b32 → a31. Strictly downward. No upward edge — the helper doesn't know what the handler does with its output. |
| §4.7 Consistency | The b32_ prefix matches what the file actually contains: Layer 1 pure logic. No misnamed file, no logic at the wrong layer. |
That table isn't decorative. It's what the agent's Done when bullet "/sama/v2/verify still reports 7/7 ✓" expands into when run against the live site. Each row corresponds to one line in b32_sama_v2_verify.ts that the agent doesn't get to touch.
Anti-fudge — the things this plan deliberately does NOT do
A naive sitemap implementation has several seductive shortcuts. The /goal rules them out explicitly:
- No second list of URLs anywhere. The temptation: keep a
SITEMAP_URLSconst next tob32_sitemap.tslisting everything. Cost: it drifts the first time someone forgets. Rule: derive fromALL_POSTSandALL_SAMA; the only hand-curated list is the small set of static routes that have no registry (/,/blog,/games, etc.) and that's intentional. - No string concatenation for XML. The temptation:
`<url><loc>${url}</loc></url>`is one line. Cost: an&or<in a URL produces invalid XML. Rule: write a tiny XML-escape helper insideb32_sitemap.tsand run every interpolation through it. The existing renderer's HTML-escape is a superset and would work, but a dedicated XML helper is cleaner Layer-1 code — and it's two lines, not a library. - No static commit of
sitemap.xml. Already covered above. The automatic property is the entire point of the feature. - No dynamic/user-specific URLs. No
/p/:slugsession pages, no/sama/verify?repo=…query-string variants, no/api/*. Only stable indexable content. - No verifier change. The §4 check logic is frozen. If a structural choice this feature makes would fail the verifier, the choice changes — the verifier doesn't.
This is what "anti-fudge" means in practice. The verifier is what catches structural drift; the /goal constraints are what catch the smaller fudges the verifier doesn't know to look for. Together they leave very little room for shortcuts that would only hurt later.
What lands when this ships
After the next deploy:
GET https://tdd.md/sitemap.xmlreturns a sitemaps.org 0.9 document with ~40 URLs (23 posts + 4 SAMA pages + spec/example/skill/verify pages + static routes).GET https://tdd.md/robots.txtreferences the sitemap on its last line.- The next time I write a blog post, it appears in the sitemap automatically — the same way it appears on
/blogautomatically — because theALL_POSTSarray is the single source of truth for both. /sama/v2/verifycontinues to report 7 ✓ / 7 on the live site.
The empirical chain — the load-bearing argument that SAMA is worth following — gets one more thing pointing at it: a sitemap entry per measurement post, indexed and rankable. That's a small thing on its own. But the way this small thing lands — /goal as contract, layer discipline as structure, verifier as gate — is the same way every other feature on this site lands. The point of the post is the workflow, not the URL list.
Next, this post turns into a postmortem
This is a plan. The companion postmortem will follow once the PR is merged and deployed, with three things the plan can't predict:
- The actual file diff (likely close to what's sketched here, but not always — agent + verifier sometimes surface a cleaner factoring mid-build).
- The verifier output before and after the merge (must read 7/7 ✓ at both timestamps).
- Whatever the
/goal's anti-fudge clauses caught that the plan missed.
If /sitemap.xml lands without surfacing anything, that's its own data point: the workflow is mature enough that the boring features stay boring. If it surfaces something — a spec gap, a verifier blind spot, a registry that wasn't where I thought — that's the next post.