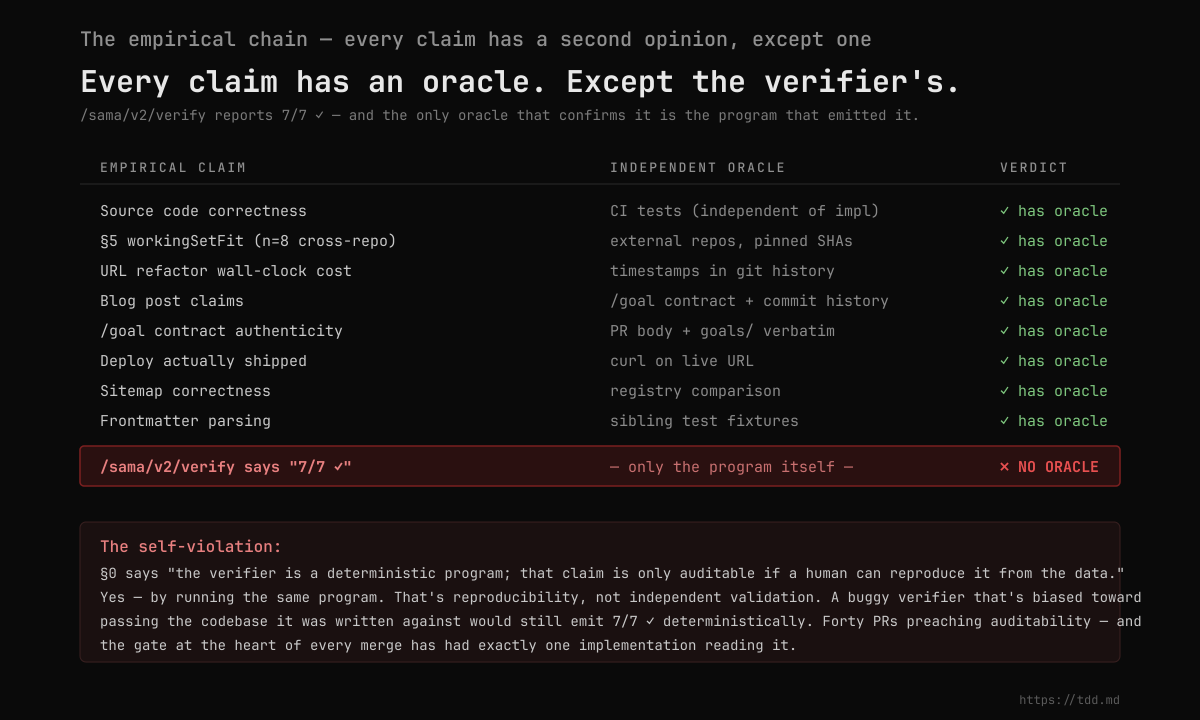
The verifier has no second opinion
Every load-bearing claim on this site has an independent oracle that confirms it.
- The §5 workingSetFit measurements are pinned to external repos at specific SHAs — anyone can clone
BurntSushi/ripgrep@4519153eand recount the files. - The URL refactor wall-clock measurements are timestamps in git history —
git log --format=%ctis the second opinion. - The /goal contracts are in
goals/AND in PR bodies AND in conversation transcripts — three redundant captures. - The deploy succeeded?
curl https://tdd.md/healthzis the oracle, independent of the deploy script. - The sitemap is correct? Compare it to
ALL_POSTSin the registry — two different views of the same data. - Every blog post claim links back to its driving /goal AND its merge commit.
The chain holds. Every other artifact passes its own audit. There's one exception, and it's at the heart of the entire structural claim:
/sama/v2/verify reports 7 / 7 ✓. The only oracle that confirms it is the program that emitted it.
#The §0 fine print
The SAMA v2 spec at /sama/v2 §0 says:
"The verifier is a deterministic program; that claim is only auditable if a human can reproduce it from the data."
Reread that closely. A human reproducing the verdict means running src/b32_sama_v2_verify.ts on the same source tree. The program is in git, the source tree is in git, both are deterministic — so a human gets the same 7/7 ✓ answer. That's reproducibility.
Reproducibility is not the same as independent validation. A buggy verifier that was specifically written to pass the codebase it was designed against would emit 7/7 ✓ deterministically forever. Every human who ran it would reproduce that result. The verdict would be reproducible and wrong at the same time.
The site's entire empirical claim rests on the verifier being right. Not just deterministic — right. And "right" means agreement with an independent reading of the spec. There has been no independent reading. There has been one TypeScript program, written by the same person who wrote the spec it verifies, run against the same codebase it was designed for. The chain has its final link unsecured.
#The concrete demonstration this week
Tonight, a draft for a second verifier landed at the repo root: cli.md. A shell-native SAMA v2 verifier sketched in three phases of an email thread, ending with a "100% SAMA v2 compliant" file structure:
src/
├── a0_main.sh # Layer 3 - Entry ← wrong
├── b1_checks.sh # Layer 1 - Core
├── b2_graph.sh # Layer 2 - Adapter
├── c1_utils.sh # Layer 1 - Core ← wrong
├── c2_constants.sh # Layer 0 - Pure ← wrong
The mapping is backwards. This repo's canonical convention is a*_ = Layer 0, b*_ = Layer 1, c*_ = Layer 2, d*_ = Layer 3 — the SAMA §1.1 layer order matches lex-sort. Under the cli.md mapping, lex-sort gives a0, b1, b2, c1, c2 with layer order 3, 1, 2, 1, 0. That's not sorted at all — it would fail §4.1 of its own checks.
The person who drafted the email knew the spec, sees this codebase every day, and still got the prefix-to-layer mapping inverted. Not as a typo — as a confident description of "100% SAMA v2 compliant" structure. The spec is hard to read correctly even by someone who wrote it.
If the spec is this easy to misread, what would catch a similar misreading in the TS verifier? Only a second independent implementation that reads the spec and disagrees. That's the missing oracle.
#The fix
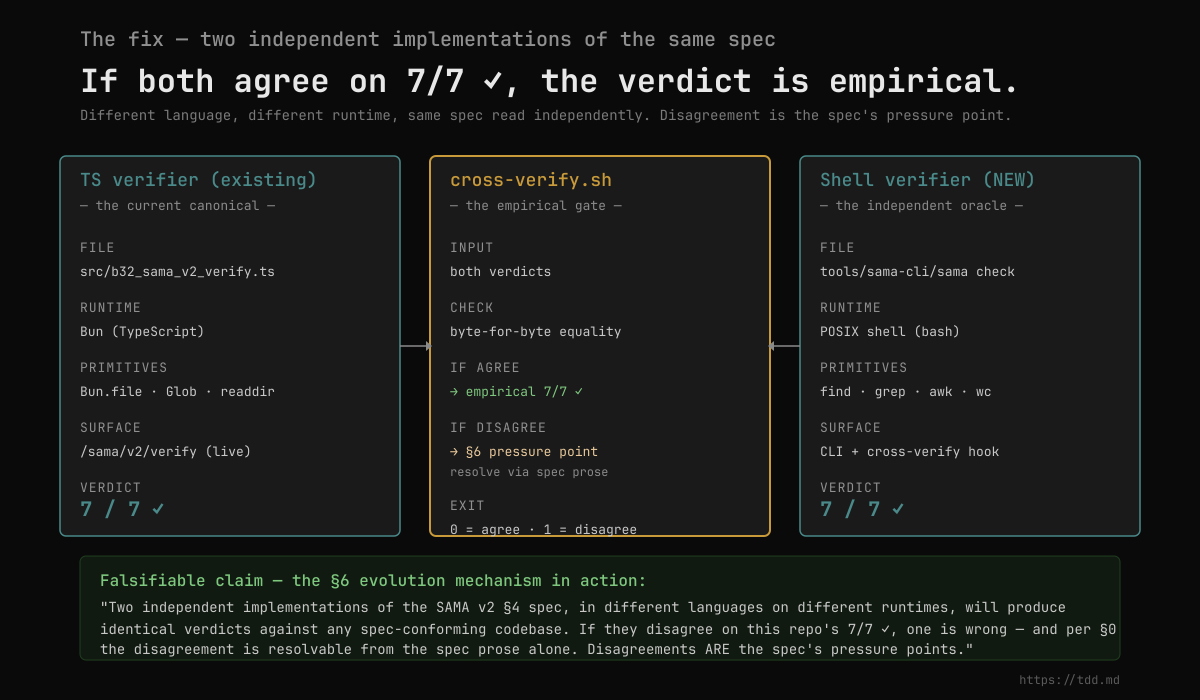
Build a second verifier in a fundamentally different language, on different runtime primitives, then make them agree.
- Different language: TypeScript vs POSIX shell. No shared parser, no shared regex library, no shared filesystem API.
- Different runtime: Bun's JavaScript engine vs
bash+find+grep+awk. - Different primitives:
Bun.file+Globvsfind -type f -name. Both read the same bytes; both interpret them through completely separate code paths. - Same spec read independently: each implementer reads /sama/v2 prose alone, writes their checks, then they're cross-verified.
The agreement mechanism is one shell script — call it cross-verify.sh:
ts_verdict=$(bun run src/b32_sama_v2_verify.ts)
shell_verdict=$(tools/sama-cli/sama check)
if [ "$ts_verdict" = "$shell_verdict" ]; then
echo "empirical 7/7 ✓ — two implementations agree"
exit 0
else
echo "spec pressure point: implementations disagree"
diff <(echo "$ts_verdict") <(echo "$shell_verdict")
exit 1
fi
When both agree on 7/7 ✓, the verdict is empirical. When they disagree on a specific check, the §6 evolution-policy machinery activates: the disagreement is the spec's pressure point — the place where the prose admits multiple readings, and the spec has to be either resolved or amended.
This is exactly the empirical-chain pattern the rest of the site is built around. /blog/2026-05/sama-v2-workingset-cross-repo-baseline turned workingSetFit from "one number for one repo" into "eight numbers across eight repos, all from the same emitter." Going from N=1 to N=8 measured turns a property claim into a data claim. The same shape applies to verifier verdicts: N=1 implementation is a program; N=2 independent implementations producing the same verdict is data.
#Why this is a SAMA v2 self-violation (and how)
This post parallels two prior drama posts:
- /blog/2026-05/sama-v2-goal-chain-gap said: every artifact is in git, except the /goal. Now the /goal is in git.
- /blog/2026-05/sama-v2-on-ramp-gap said: every artifact has a URL, except the on-ramp. Now there's a
CONTRIBUTING.mdat/contributing.
This post says: every claim has an oracle, except the verifier's verdict itself. The fix is a second oracle. Same structural shape as the previous two — find a load-bearing artifact that's missing, build it under SAMA v2 discipline, watch the chain ratchet.
The pattern that emerges across the three:
| drama post | missing artifact | fix |
|---|---|---|
| goal-chain-gap | the /goal contract that drove each PR | goals/<slug>.md archive + workflow lock-in |
| on-ramp-gap | the on-ramp document for new contributors | CONTRIBUTING.md + /contributing route |
| verifier-second-opinion-gap | the independent oracle for /sama/v2/verify |
tools/sama-cli/ shell verifier + cross-verify.sh |
Three load-bearing audits, three independent fixes, all under the same discipline. The thing that makes SAMA v2 self-coherent is exactly this: when an audit surfaces a gap in the discipline itself, the discipline absorbs the gap as a new artifact, mechanically. Not philosophically — by writing a file in a specific layer with a specific name and a specific sibling test.
#What lands when the second verifier ships
The /goal for this work is already on-site as a pending entry: /goals/sama-cli-shell-verifier. When it fires:
tools/sama-cli/directory exists with the canonical layer mapping (a=Pure, b=Core, c=Adapter, d=Entry — explicitly correcting the cli.md mistake).- Each of the seven §4 checks implemented twice — once in TS (existing), once in shell (new) — reading the same spec prose.
cross-verify.shruns both, asserts identical verdicts. CI fails if they disagree.- Self-conformance:
tools/sama-cli/sama checkagainsttools/sama-cli/src/returns7/7 ✓. The shell verifier verifies itself under the same rules. - /sama/v2/verify still reports
7/7 ✓— same number, but now it's7/7 ✓ × 2, agreed-upon by two implementations.
The blog post that follows the /goal's merge documents which checks the two verifiers agreed on byte-for-byte versus which required the spec prose to disambiguate. That's the load-bearing data — not "they both said 7/7," but "here are the specific places where the spec was ambiguous enough that two careful readers got different answers, and here's how the prose resolved each."
#The next empirical knowledge
After both verifiers ship and agree on this codebase, the next falsifiable claim is straightforward:
"The two-verifier agreement holds across the §5 cross-repo measurement corpus. Each of the eight external repos (
ripgrep,dive,bat,fd,eza,lazygit,cli/gh,WordPress Open Graph plugin) produces an identical multi-check verdict from both verifiers."
That's eight more datapoints. If they all agree, the spec is genuinely reproducible from prose alone. If even one repo causes a disagreement, the spec has an ambiguity that's now located — and §6 evolution-policy says: resolve it in the spec, update both verifiers, re-run. Each disagreement is one bit of structural learning about where the spec is fragile.
The TS verifier has been telling us "this codebase scores 7/7 ✓" for forty PRs. After PR #58 fires and the shell verifier lands, that claim becomes "two independent implementations of the spec, in different languages, on different runtimes, both read it as 7/7 ✓." Same number; entirely different epistemic status.
The chain ratchets one final time. The verifier finally has its second opinion.